


Google, Amazon and Microsoft are the three big players in cloud computing. The cloud comes into question for almost all possible application scenarios, for example the hosting of company software, web applications and applications for mobile devices. In addition to these classics, the cloud also plays an important role as an enabler for the Internet of Things, blockchain or artificial intelligence.
In the following, we will look at the cloud provider Microsoft Azure with a view to the possibilities of building a modern business intelligence or data platform for companies. The many services of Microsoft Azure allow countless possible uses and are difficult to survey in full, even for cloud experts. Microsoft therefore proposes various reference models for data platforms or business intelligence systems with different orientations. The most comprehensive reference model is the one for real-time analytics.
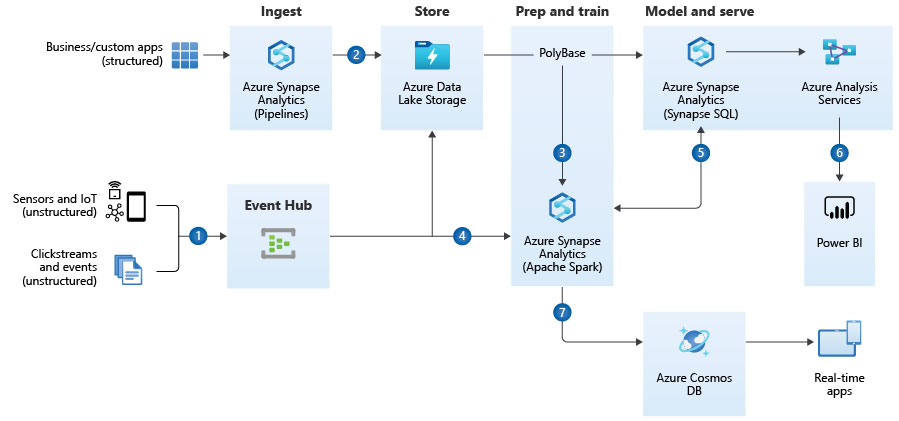
Azure Reference Architecture for Realtime Analytics
This reference architecture from Microsoft on Azure builds on the reference architecture for modern data warehouse systems based on Microsoft Azure. Microsoft Azure Synapse is the dominant component from data integration and data storage to data analysis and integration of data science methodology.
Azure Synapse as ETL tool
In contrast to older Microsoft reference models, Azure Synapse is used here as an ETL tool instead of Azure Data Factory. Azure Synapse has partly inherited the data integration functionalities from Azure Data Factory, even though Data Factory is still considered the more powerful ETL tool today. Azure Synapse moves further away from the old SSIS logic and also does not offer integration of SSIS packages; in addition, some connections between Data Factory and Synapse are different.
Selection of databases
Azure Blob Storage is used as a cache or staging layer, but in the shell of the Azure Data Lake, which adds a user layer to the pure storage and simplifies the management of the storage. As a staging layer or for data historisation, blob storage is a cost-efficient method, but may still be debated on individual consideration in terms of necessity.
Azure Synapse appears to be the sensible solution in this reference architecture, as not only the pipelines of Synapse, but also the SQL engine as well as the Spark engine (via Python notebooks) can be used for the application of machine learning (e.g. for recommender systems). Here, Azure Synpase fully plays out its possibilities as the core of a modern, intelligent data warehouse architecture.
Azure Analysis Service
In this reference architecture, the Azure Analysis Service is proposed by Microsoft as a cube-generating machine. The following applies: The Analysis Service tends to be unnecessary for pure use with Power BI, but if users are to be able to carry out complex, pre-calculated analyses in MS Excel, then the Analysis Service pays off.
Azure Cosmos DB
The Azure Cosmos DB is most comparable to MongoDB Atlas (the cloud version of MongoDB, which is actually hosted on-premise). It is a NoSQL database that can also query particularly large amounts of data at very high speed via data documents in JSON file format. It is currently considered the fastest database in terms of read access and plays out all the advantages when it comes to mass provision of data to other applications. Companies that provide their customers with mobile applications that require millions of parallel data accesses rely on Cosmos DB.
Azure Event Hub
The reference architecture for real-time analytics supplements the reference architecture for data warehousing with the Event Hub. This only makes sense for deployment scenarios in which data streaming plays a central role. In simple terms, data streaming involves many small, event-triggered incremental data loading processes or requirements (events) that can be executed almost in real time. This can be of great importance in web shops and mobile applications, e.g. if offers for customers are to be displayed in a highly individualised way or if market data are to be displayed and interacted with (e.g. trading of securities). Streaming tools bundle just such events (or their data chunks) into data streaming channels (partitions), which can then be taken up by many services (consumer groups / receivers). Data streaming is also a necessary setup, especially if a company has a microservices architecture in which many small services (mostly as Docker containers) serve as a decentralised overall structure. Each service can appear as a sender and/or receiver via Apache Kafka. The Azure Event Hub is used to cache and manage the data streams from the event senders into the Azure Blob Storage or Data Lake or into Azure Synapse, where they can be passed on or stored for deeper analysis.
Fancy the reference architecture? What you should consider beforehand:
Reference architectures are to be understood exactly as that: As a reference. Under no circumstances should this architecture be adopted unreflectively for a company, but should be brought into line with the data strategy beforehand, and at the very least these questions should be clarified:
- Which data sources are available and will be available in the future?
- Which use cases do I have for the business intelligence or data platform?
- What financial and technical resources may be available?
Furthermore, architects should be aware that, unlike in the more inert on-premise world, could-services are fast-moving. For example, the 2019/2020 reference architecture looked somewhat different, including Databricks on Azure as a system for advanced analytics; today, this position in the reference model seems to have been completely replaced by Azure Synapse. Understand this as a proposal that we need to work on together.



{kind=link}